
Die OpenAI-API ermöglicht den Bau eigener KI-Chats mit ChatGPT Turbo. Mit der sgcWebSockets-Bibliothek ist die Interaktion mit der API sehr einfach — bei einer Chat-Unterhaltung liefert das Modell eine Chat-Completion-Antwort zurück.
ChatGPT-Delphi-Beispiel
OpenAI verlangt einen Request, in dem du die zu ChatGPT Turbo zu sendenden Nachrichten übergibst, die Temperature (für mehr oder weniger zufällige Ausgaben usw.). Unten eine Liste der verfügbaren Parameter.
- model: (Erforderlich) ID des zu verwendenden Modells. Siehe die Model-Endpoint-Kompatibilitätstabelle für Details, welche Modelle mit der Chat-API funktionieren.
- messages: (Erforderlich) Die Nachrichten, für die Chat-Completions generiert werden sollen, im Chat-Format.
- temperature: Welche Sampling-Temperatur, zwischen 0 und 2. Höhere Werte wie 0.8 machen die Ausgabe zufälliger, niedrigere wie 0.2 fokussierter und deterministischer.
- top_p: Eine Alternative zum Temperature-Sampling, Nucleus Sampling genannt - das Modell betrachtet die Token mit top_p-Wahrscheinlichkeitsmasse. 0.1 heißt also: nur die Token, die die obersten 10% Wahrscheinlichkeitsmasse ausmachen.
- n: Wie viele Chat-Completion-Auswahlmöglichkeiten pro Eingabenachricht generiert werden.
- stream: Wenn gesetzt, werden partielle Nachrichten-Deltas gesendet, wie in ChatGPT. Tokens werden als Daten-only-Server-Sent-Events geschickt, sobald sie verfügbar sind; der Stream endet mit einer data: [DONE]-Nachricht. Siehe das OpenAI Cookbook für Beispielcode.
- stop: Bis zu 4 Sequenzen, bei denen die API aufhört, weitere Token zu generieren.
- max_tokens: Maximale Anzahl Token, die in der Chat-Completion generiert werden. Die Gesamtlänge aus Input-Token und generierten Token ist durch die Context-Länge des Modells begrenzt.
- presence_penalty: Zahl zwischen -2.0 und 2.0. Positive Werte bestrafen neue Token basierend darauf, ob sie bereits im bisherigen Text auftauchen - erhöht die Wahrscheinlichkeit, dass das Modell über neue Themen spricht.
- frequency_penalty: Zahl zwischen -2.0 und 2.0. Positive Werte bestrafen neue Token basierend auf ihrer bisherigen Häufigkeit im Text - verringert die Wahrscheinlichkeit, dass das Modell dieselbe Zeile wörtlich wiederholt.
- logit_bias: Beeinflusse die Wahrscheinlichkeit, mit der bestimmte Token in der Completion erscheinen. Akzeptiert ein JSON-Objekt, das Token (anhand ihrer Token-ID im Tokenizer) einem Bias-Wert von -100 bis 100 zuordnet. Mathematisch wird der Bias vor dem Sampling auf die vom Modell generierten Logits addiert. Der genaue Effekt variiert je Modell, aber Werte zwischen -1 und 1 sollten die Auswahlwahrscheinlichkeit erhöhen oder verringern; Werte wie -100 oder 100 führen zu einem Ban bzw. einer exklusiven Auswahl des Tokens.
- user: Eine eindeutige Kennung deines Endnutzers, die OpenAI helfen kann, Missbrauch zu überwachen und zu erkennen.
Unten ein einfaches Beispiel, das eine Nachricht an ChatGPT Turbo sendet.
procedure SendMessageChatGPT(const aMessage: string);
var
i: Integer;
oMessages: TsgcOpenAIArray_Request_Completion_Messages;
oMessage: TsgcOpenAIClass_Request_Completion_Message;
oRequest: TsgcOpenAIClass_Request_ChatCompletion;
oResponse: TsgcOpenAIClass_Response_ChatCompletion;
begin
oRequest := TsgcOpenAIClass_Request_ChatCompletion.Create;
Try
// ... Modell
oRequest.Model := 'gpt-3.5-turbo';
// ... Nachricht erstellen
oMessage := TsgcOpenAIClass_Request_Completion_Message.Create;
oMessage.Content := aMessage;
oMessages := oRequest.Messages;
SetLength(oMessages, 1);
oMessages[0] := oMessage;
oRequest.Messages := oMessages;
// ... Nachricht senden
oResponse := OpenAI.CreateChatCompletion(oRequest);
// ... Antwort verarbeiten
for i := 0 to Length(oResponse.Choices) - 1 do
DoLog('[' + oResponse.Choices[i]._Message.Role + '] ' + oResponse.Choices[i]._Message.Content);
Finally
oRequest.Free
End;
End;
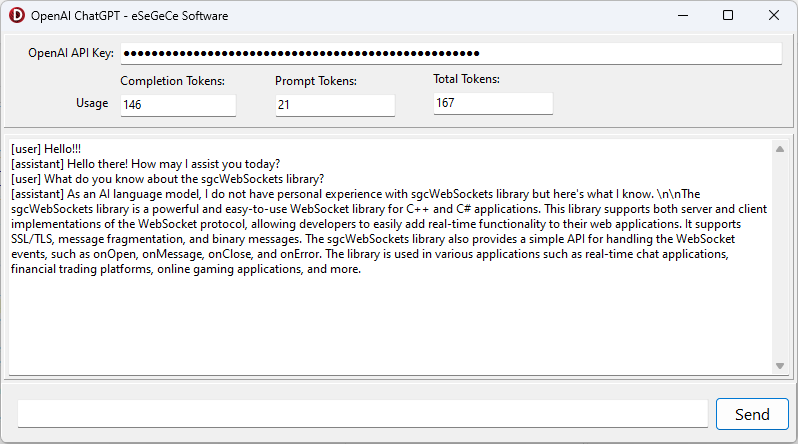
Unten findest du die kompilierte Demo für Windows mit der sgcWebSockets OpenAI Delphi-Bibliothek.