
La API de OpenAI te permite construir tus propios chats con IA usando ChatGPT Turbo. Con la librería sgcWebSockets es muy fácil interactuar con la API: dada una conversación de chat, el modelo devolverá una respuesta de chat completion.
Ejemplo de ChatGPT en Delphi
OpenAI requiere construir una solicitud donde pasas los mensajes que se enviarán a ChatGPT Turbo, la temperature (para obtener una salida más o menos aleatoria)... a continuación tienes una lista de los parámetros disponibles.
- model: (obligatorio) ID del modelo a usar. Consulta la tabla de compatibilidad de modelos y endpoints para ver qué modelos funcionan con la Chat API.
- messages: (obligatorio) los mensajes para los que generar chat completions, en formato chat.
- temperature: qué temperatura de sampling usar, entre 0 y 2. Valores altos como 0.8 hacen que la salida sea más aleatoria, mientras que valores bajos como 0.2 la hacen más enfocada y determinista.
- top_p: alternativa al sampling con temperature, llamada nucleus sampling, donde el modelo considera los resultados de los tokens cuya masa de probabilidad acumulada es top_p. Por ejemplo, 0.1 significa que sólo se consideran los tokens que comprenden el 10% superior de la masa de probabilidad.
- n: cuántas opciones de chat completion generar por cada mensaje de entrada.
- stream: si se activa, se enviarán deltas parciales de mensaje, como en ChatGPT. Los tokens se enviarán como server-sent events de sólo datos a medida que estén disponibles, y el stream terminará con un mensaje data: [DONE]. Consulta el OpenAI Cookbook para ejemplos de código.
- stop: hasta 4 secuencias en las que la API dejará de generar tokens.
- max_tokens: número máximo de tokens a generar en el chat completion. La longitud total de los tokens de entrada y los generados está limitada por la longitud de contexto del modelo.
- presence_penalty: número entre -2.0 y 2.0. Los valores positivos penalizan los nuevos tokens en función de si aparecen ya en el texto, aumentando la probabilidad de que el modelo hable de temas nuevos.
- frequency_penalty: número entre -2.0 y 2.0. Los valores positivos penalizan los nuevos tokens en función de su frecuencia en el texto, reduciendo la probabilidad de que el modelo repita la misma línea literalmente.
- logit_bias: modifica la probabilidad de que ciertos tokens aparezcan en el completion. Acepta un objeto json que mapea tokens (especificados por su token ID en el tokenizer) a un valor de bias asociado entre -100 y 100. Matemáticamente, el bias se añade a los logits generados por el modelo antes del sampling. El efecto exacto varía según el modelo, pero los valores entre -1 y 1 deberían reducir o aumentar la probabilidad de selección; valores como -100 o 100 deberían resultar en una prohibición o selección exclusiva del token correspondiente.
- user: identificador único que representa al usuario final, lo que puede ayudar a OpenAI a monitorizar y detectar abusos.
A continuación tienes un ejemplo simple enviando un mensaje a ChatGPT-Turbo.
procedure SendMessageChatGPT(const aMessage: string);
var
i: Integer;
oMessages: TsgcOpenAIArray_Request_Completion_Messages;
oMessage: TsgcOpenAIClass_Request_Completion_Message;
oRequest: TsgcOpenAIClass_Request_ChatCompletion;
oResponse: TsgcOpenAIClass_Response_ChatCompletion;
begin
oRequest := TsgcOpenAIClass_Request_ChatCompletion.Create;
Try
// ... model
oRequest.Model := 'gpt-3.5-turbo';
// ... create message
oMessage := TsgcOpenAIClass_Request_Completion_Message.Create;
oMessage.Content := aMessage;
oMessages := oRequest.Messages;
SetLength(oMessages, 1);
oMessages[0] := oMessage;
oRequest.Messages := oMessages;
// ... send message
oResponse := OpenAI.CreateChatCompletion(oRequest);
// ... process response
for i := 0 to Length(oResponse.Choices) - 1 do
DoLog('[' + oResponse.Choices[i]._Message.Role + '] ' + oResponse.Choices[i]._Message.Content);
Finally
oRequest.Free
End;
End;
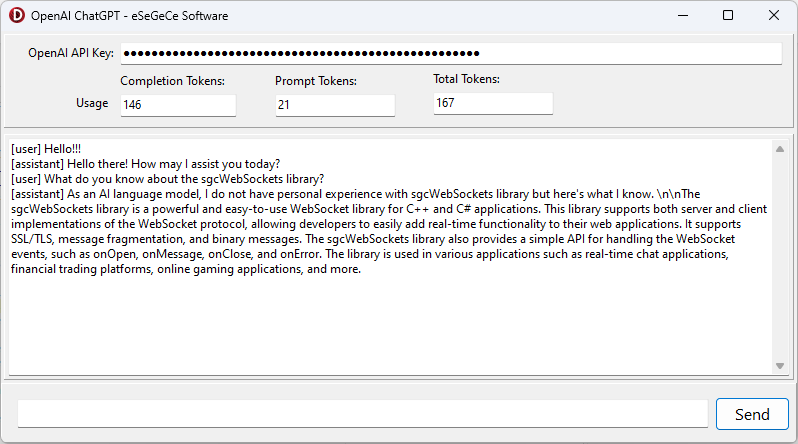
A continuación tienes la demo compilada para Windows usando la librería OpenAI para Delphi de sgcWebSockets.